Deep learning and variational inversion to quantify and attribute climate change (CIRC23)#
General Modelling Special Issue Python
![]()
![]()
![]()
![]()
![]()
Context#
Purpose#
The purpose of the notebook is to explore the process and demonstrate the power of using a climate simulation and observation data with a convolutional neural network in the detection of climate change and a variational inversion approach to attribute forcings to changes in global mean surface temperatures from 1900 to 2014.
Description#
The modelling pipeline consists of the following three procedures: data acquisition & preprocessing, climate change detection and climate change attribution.
Observations (OBS) of the 2 m air temperature over the continents from HadCRUT4 (Morice et al., 2012) blended with sea surface temperature from HadISST412 (Rayner et al., 2003). The outputs of ocean-atmosphere general circulation models from the Coupled Model Intercomparison Project 6 (CMIP6) (Eyring et al., 2016) are also acquired and divided into several categories based on used forcings: single-forcing simulations utilizing greenhouse gas concentration (GHG), single-forcing simulations utilizing anthropogenic aerosols (AER), single-forcing simulations utilizing natural forcings such as volcanic aerosols and solar variations (NAT), and historical simulations using all the external forcings (HIST). The data is converted into an annual mean and is spatially averaged over the globe to obtain the global mean surface temperature (GMST). Then the mean temperatures of the pre-industrial time period (1850-1900) are removed from the period of interest (1900-2014) to obtain the temperature anomalies.
To determine the relation between the GMST of the single-forcing models GHG, AER, NAT to that of HIST, a convolutional neural network (CNN) is trained. The CNN uses the single-forcing model simulations as input of size (3,115), and uses the HIST simulations as the target of size (1,115). To estimate whether the added non-linearities of the CNN model improve the model performance, a simple linear model is trained using the same inputs and targets.
The trained CNN is then used to obtain the variational inversion using the backpropagation algorithm. In this case, OBS time series are used and linked to the single-forcing models (GHG, AER, NAT).
The model was implemented in Python 3.10 using PyTorch v1.13.0. Further details can be found in the Environmental Data Science paper “Detection and attribution of climate change: A deep learning and variational approach”.
Highlights#
Acquire, pre-process and visualize the observation and climate simulation data.
Train a CNN model to predict the historical simulation time series (HIST) given the three single-forcing model simulations (GHG, AER, NAT).
Use the trained CNN model combined with a variational approach to estimate the three forcings given observation (OBS) data.
Abbreviations#
OBS - observations
AER - single forcing simulations utilizing anthropogenic aerosols
GHG - single forcing simulations utilizing greenhouse gases
NAT - single forcing simulations utilizing natural forcings
HIST - historical simulations using all external forcings
CMIP6 - Coupled Model Intercomparison Project 6
GMST - Global Mean Surface Temperature
CNN - Convolutional Neural Network
MSE - Mean Squared Error
Contributions#
Notebook#
Viktor Domazetoski (author), University of Göttingen, @ViktorDomazetoski
Andrés Zúñiga-González (author), University of Cambridge, @ancazugo
Owen Allemang (author), University of Cambridge, @SkirOwen
Meghna Asthana (reviewer), The Alan Turing Institute, @asthanameghna
Nick Homer (reviewer), The University of Edinburgh, @ NHomer-Edi
Devanjan Bhattacharya (reviewer), The University of Edinburgh, @dbhatedin
Modelling codebase#
Constantin Bône (author), UMR LOCEAN, Sorbonne Université, UMR ISIR, Sorbonne Université
Guillaume Gastineau (author), UMR LOCEAN, Sorbonne Université
Sylvie Thiria (author), UMR LOCEAN, Sorbonne Université
Patrick Gallinari (author), UMR ISIR, Sorbonne Université, Criteo AI Lab
Modelling publications#
Constantin Bône, Guillaume Gastineau, Sylvie Thiria, and Patrick Gallinari. Detection and attribution of climate change: a deep learning and variational approach. Environmental Data Science, 1:e27, 2022. doi:10.1017/eds.2022.17.
Dataset documentation#
V. Eyring, S. Bony, G. A. Meehl, C. A. Senior, B. Stevens, R. J. Stouffer, and K. E. Taylor. Overview of the coupled model intercomparison project phase 6 (cmip6) experimental design and organization. Geoscientific Model Development, 9(5):1937–1958, 2016. URL: https://gmd.copernicus.org/articles/9/1937/2016/, doi:10.5194/gmd-9-1937-2016.
Colin P. Morice, John J. Kennedy, Nick A. Rayner, and Phil D. Jones. Quantifying uncertainties in global and regional temperature change using an ensemble of observational estimates: the hadcrut4 data set. Journal of Geophysical Research: Atmospheres, 2012. URL: https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/2011JD017187, arXiv:https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2011JD017187, doi:https://doi.org/10.1029/2011JD017187.
N. A. Rayner, D. E. Parker, E. B. Horton, C. K. Folland, L. V. Alexander, D. P. Rowell, E. C. Kent, and A. Kaplan. Global analyses of sea surface temperature, sea ice, and night marine air temperature since the late nineteenth century. Journal of Geophysical Research: Atmospheres, 2003. URL: https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/2002JD002670, arXiv:https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2002JD002670, doi:https://doi.org/10.1029/2002JD002670.
Mark Richardson, Kevin Cowtan, and Richard J Millar. Global temperature definition affects achievement of long-term climate goals. Environmental Research Letters, 13(5):054004, apr 2018. URL: https://dx.doi.org/10.1088/1748-9326/aab305, doi:10.1088/1748-9326/aab305.
Source code#
The notebook contributors acknowledge the authors of the paper for providing a reproducible and public code available at ConstantinBone/detection-and-attribution-of-climate-change-a-deep-learning-and-variational-approach. The source code of the paper was adapted to this notebook.
Load libraries#
Show code cell source
"""Math & Data Libraries"""
import os
import numpy as np
import random
import pandas as pd
import netCDF4 as nc4
from scipy import signal
import pooch
""" ML Libraries"""
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.autograd import Variable
import pickle
""" Miscellaneous Libraries"""
from tqdm import tqdm
import warnings
"""Visualization Libraries"""
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("whitegrid", {"grid.color": "0.5", "axes.edgecolor": "0.2"})
color_palette = [
"#FF8853",
"#FFE174",
"#007597",
"#C1C36D",
"#00A697",
"#BC97E0",
"#ffc0bf",
]
warnings.filterwarnings(action="ignore")
Settings#
Variables#
We start definining model settings in a dictionary of dictionaries. It contains the number of simulations per forcing per model, and the long name.
model_dict = {
"IPSL": {
"hist-GHG": 10,
"hist-aer": 10,
"hist-nat": 10,
"historical": 32,
"long_name": "IPSL-CM6A-LR",
},
"ACCESS": {
"hist-GHG": 3,
"hist-aer": 3,
"hist-nat": 3,
"historical": 30,
"long_name": "ACCESS-ESM1-5",
},
"CESM2": {
"hist-GHG": 3,
"hist-aer": 2,
"hist-nat": 3,
"historical": 11,
"long_name": "CESM2",
},
"BCC": {
"hist-GHG": 3,
"hist-aer": 3,
"hist-nat": 3,
"historical": 3,
"long_name": "BCC-CSM2-MR ",
},
"CanESM5": {
"hist-GHG": 50,
"hist-aer": 30,
"hist-nat": 50,
"historical": 65,
"long_name": "CanESM5",
},
"FGOALS": {
"hist-GHG": 3,
"hist-aer": 3,
"hist-nat": 3,
"historical": 6,
"long_name": "FGOALs-g3",
},
"HadGEM3": {
"hist-GHG": 4,
"hist-aer": 4,
"hist-nat": 4,
"historical": 5,
"long_name": "HadGEM3",
},
"MIRO": {
"hist-GHG": 3,
"hist-aer": 3,
"hist-nat": 3,
"historical": 50,
"long_name": "MIROC6",
},
"ESM2": {
"hist-GHG": 5,
"hist-aer": 5,
"hist-nat": 5,
"historical": 7,
"long_name": "MRI-ESM2",
},
"NorESM2": {
"hist-GHG": 3,
"hist-aer": 3,
"hist-nat": 3,
"historical": 3,
"long_name": "NorESM2-LM",
},
"CNRM": {
"hist-GHG": 9,
"hist-aer": 10,
"hist-nat": 10,
"historical": 30,
"long_name": "CNRM-CM6-1",
},
"GISS": {
"hist-GHG": 10,
"hist-aer": 12,
"hist-nat": 20,
"historical": 19,
"long_name": "GISS-E2-1-G",
},
}
model_list = [
"CanESM5",
"CNRM",
"IPSL",
"ACCESS",
"BCC",
"FGOALS",
"HadGEM3",
"MIRO",
"ESM2",
"NorESM2",
"CESM2",
"GISS",
]
Classes#
We use torch.nn and torch.utils.data modules to define linear (baseline) and CNN models, and datasets, respectively.
Show code cell source
class CNN_Model(nn.Module):
"""
A class for a Convolutional Neural Network.
The CNN consists of three convolutional layers, each with a padding of 5
and a kernel size of 11 that are non-linearly transformed using a hyperbolic tangent function.
---
Parameters
----------
size_channel : int
length of the layer (number of neurons) (defaults to 10)
bias: boolean
whether to add a learnable bias to the input (defaults to True)
Methods
-------
forward(X):
Defines the computation performed at every call.
"""
def __init__(self, size_channel=10, bias=True):
super(CNN_Model, self).__init__()
self.tanh = nn.Tanh()
self.conv1 = nn.Conv1d(
3, size_channel, kernel_size=11, bias=bias, padding=5
) # The input layer has a size of 3 due to the three forcings [ghg, aer, nat]
self.conv2 = nn.Conv1d(
size_channel, size_channel, kernel_size=11, bias=bias, padding=5
)
self.conv3 = nn.Conv1d(
size_channel, 1, kernel_size=11, bias=bias, padding=5
) # The output layer has a size of 1 as the target [hist]
def forward(self, x):
"""
Defines the computation performed at every call.
The input goes through 2 convolutional and hyperbolic tangent layers before being
transformed to float and transformed to a tensor of shape (batch_size, N_years)
---
Parameters
----------
x : torch.tensor of shape (batch_size, N_forcings, N_years), where the batch size defaults to 100, N_forcings equals 3 and represents the three forcings [ghg, aer, nat], and N_years equals 115 and represents the data from 1900-2014.
input tensor containing the batch of data for the three forcings over the time span of interest.
Returns
-------
Output of computation : torch.tensor of shape (batch_size, N_years)
output tensor that tries to predict the historical simulations using all the external forcings as varying boundary conditions
"""
x = self.conv1(x)
x = self.tanh(x)
x = self.conv2(x)
x = self.tanh(x)
x = x.float()
x = self.conv3(x)[:, 0, :]
return x
class Linear_Model(nn.Module):
"""
A class for a Simple Linear Module used for comparison.
---
Parameters
----------
bias: boolean
whether to add a learnable bias to the input (defaults to False)
Methods
-------
forward(X):
Defines the computation performed at every call.
"""
def __init__(self, bias=False):
super(Linear_Model, self).__init__()
self.linear = nn.Linear(3, 1, bias=bias)
def forward(self, X):
"""
Defines the computation performed at every call.
The input goes through a linear layer before being transformed to a tensor of shape [batch_size, N_years]
---
Parameters
----------
x : torch.tensor of size (batch_size, N_forcings, N_years), where the batch size defaults to 100, N_forcings equals 3 and represents the three forcings [ghg, aer, nat], and N_years equals 115 and represents the data from 1900-2014.
input tensor containing the batch of data for the three forcings over the time span of interest.
Returns
-------
Output of computation : torch.tensor of shape (batch_size, N_years)
output tensor that tries to predict the historical simulations using all the external forcings as varying boundary conditions
"""
x = self.linear(X.transpose(1, 2))
return x[:, :, 0]
class MonDataset(Dataset):
"""
A pytorch Dataset class that is used as an input for the CNN DataLoader.
---
Parameters
----------
ghg: list of length 12, with one torch.tensor of shape (N_simu, N_years) for each model. N_simu is dependent on the model and ranges from 3 to 50, and N_years equals 115 and represents the data from 1900-2014
A list of tensors, containing the greenhouse gas (GHG) single forcing simulations for each model over the time span of interest.
aer: list of length 12, with one torch.tensor of shape (N_simu, N_years) for each model. N_simu is dependent on the model and ranges from 3 to 50, and N_years equals 115 and represents the data from 1900-2014
A list of tensors, containing the aerosol (AER) single forcing simulations for each model over the time span of interest.
nat: list of length 12, with one torch.tensor of shape (N_simu, N_years) for each model. N_simu is dependent on the model and ranges from 2 to 30, and N_years equals 115 and represents the data from 1900-2014
A list of tensors, containing the natural (NAT) single forcing simulations for each model over the time span of interest.
historical: list of length 12, with one torch.tensor of shape (N_simu, N_years) for each model. N_simu is dependent on the model and ranges from 3 to 65, and N_years equals 115 and represents the data from 1900-2014
A list of tensors, containing the historical (HIST) simulations using all the external forcings as varying boundary conditions for each model over the time span of interest.
model_of_interest: int
The index of the model to exclude (include) when creating the train (test) dataset. Set to -1 in order to include all models.
dataset_type: str, one of ["train", "test"]
Whether to create a train or test dataset
Methods
-------
len(N_samples):
Defines the number of samples returned.
__getitem__():
Fetch a random data sample.
"""
def __init__(
self, ghg, aer, nat, historical, model_of_interest=-1, dataset_type="train"
):
self.ghg = ghg
self.aer = aer
self.nat = nat
self.historical = historical
self.dataset_type = dataset_type
self.model_of_interest = model_of_interest
def __len__(self, n_samples=50000):
"""
Defines the number of samples returned.
---
Parameters
----------
n_samples: int
Number of samples to return. Defaults to 5e4.
Returns
-------
Number of samples : int
"""
return n_samples
def __getitem__(self, idx):
"""
Fetch a random data sample.
If self.model_of_interest is -1, no models are excluded and in both the train and test sample we randomly choose a model and then randomly choose a simulation for each forcing to add to the dataset.
Otherwise, if we want to exclude a specific model, within the train set we randomly choose a model that is not the model we want to exclude, while in the test set we only acquire data from that model.
---
Returns
-------
X : torch.tensor of shape (N_forcings, N_years), where N_forcings equals 3 and represents the three forcings [ghg, aer, nat], and N_years equals 115 and represents the data from 1900-2014.
a tensor containing a random sample of the simulation data for the three forcings over the time span of interest.
y : torch.tensor of shape (N_years, ) where N_years equals 115 and represents the data from 1900-2014
a tensor containing a random sample of the historical simulation data over the time span of interest.
model_idx : int
the index of the model used to acquire the random sample
"""
if self.dataset_type == "train":
# We sample a random index between 0 and 11 until we find one that is not the model we want to exclude.
while True:
model_idx = random.randint(0, len(self.ghg) - 1)
if model_idx != self.model_of_interest:
break
elif self.dataset_type == "test":
# We take the index of the model we want to include.
model_idx = self.model_of_interest
# If the model is -1, then all models can potentially be included, thus we randomly sample one of the 12 models
if model_idx == -1:
model_idx = random.randint(0, len(self.ghg) - 1)
# We sample a simulation of each forcing of the model
ghg_sample = self.ghg[model_idx][
random.randint(0, self.ghg[model_idx].shape[0] - 1)
]
aer_sample = self.aer[model_idx][
random.randint(0, self.aer[model_idx].shape[0] - 1)
]
nat_sample = self.nat[model_idx][
random.randint(0, self.nat[model_idx].shape[0] - 1)
]
hist_sample = self.historical[model_idx][
random.randint(0, self.historical[model_idx].shape[0] - 1)
]
x = torch.stack((ghg_sample, aer_sample, nat_sample)).float()
y = hist_sample.float()
return x, y, model_idx
class MonDataset_Inverse(Dataset):
"""
A pytorch Dataset class that is used as an input for the Inverse model DataLoader.
---
Parameters
----------
ghg: torch.tensor of shape (N_simu, N_years) for one climate model. N_simu is dependent on the model and ranges from 3 to 50, and N_years equals 115 and represents the data from 1900-2014
A tensor, containing the greenhouse gas (GHG) single forcing simulations for one model over the time span of interest.
aer: ltorch.tensor of shape (N_simu, N_years) for one climate model. N_simu is dependent on the model and ranges from 3 to 50, and N_years equals 115 and represents the data from 1900-2014
A tensor, containing the aerosol (AER) single forcing simulations for for one model over the time span of interest.
nat: torch.tensor of shape (N_simu, N_years) for one climate model. N_simu is dependent on the model and ranges from 2 to 30, and N_years equals 115 and represents the data from 1900-2014
A tensor, containing the natural (NAT) single forcing simulations for one model over the time span of interest.
Methods
-------
len(N_samples):
Defines the number of samples returned.
__getitem__():
Fetch a random data sample.
"""
def __init__(self, ghg, aer, nat):
self.ghg = ghg
self.aer = aer
self.nat = nat
def __len__(self, n_samples=100):
"""
Defines the number of samples returned.
---
Parameters
----------
N_samples: int
Number of samples to return. Defaults to 5e4.
Returns
-------
Number of samples : int
"""
return n_samples
def __getitem__(self, idx):
"""
Fetch a random data sample.
---
Returns
-------
X : torch.tensor of shape (N_forcings, N_years), where N_forcings equals 3 and represents the three forcings [ghg, aer, nat], and N_years equals 115 and represents the data from 1900-2014.
a tensor containing a random sample of the simulation data for the three forcings over the time span of interest.
"""
ghg_sample = self.ghg[random.randint(0, self.ghg.shape[0] - 1)]
aer_sample = self.aer[random.randint(0, self.aer.shape[0] - 1)]
nat_sample = self.nat[random.randint(0, self.nat.shape[0] - 1)]
X = torch.stack((ghg_sample, aer_sample, nat_sample)).float()
return X
Functions#
We also define some utils functions to load models/simulations, train models and compute spatial calculations.
Show code cell source
def calculate_spatial_mean(data):
"""
Calculate the spatially weighted mean over the globe.
---
Parameters
----------
data : np.array of shape (N_years, latitude, longitude)
temporal data covering the entire globe
Returns
-------
obs_data_mean : np.array of shape (N_years)
Annual spatially averaged observation data from 1900 to 2020.
"""
data_mean = np.zeros((data.shape[0])) # Initialize np array to keep the results
latitude = np.linspace(
-87.5, 87.5, 36
) # Initialize array that contains the mean latitude coordinates of the 5 degree bands used in the spatial weighting
div = 0
for j in range(
36
): # The latitude dimension of the data is split into 36 parts of 5 degrees which is why we loop throught 36 indices
for k in range(
72
): # Similarly, the longitude dimension of the data is split into 72 parts of 5 degrees which is why we loop throught 72 indices
data_mean += data[:, j, k] * np.cos(np.radians(latitude[j]))
div += np.cos(np.radians(latitude[j]))
data_mean /= div
return data_mean
def get_observation_data(data_dir):
"""
Get annual observation (OBS) data of the 2 m air temperature over the continent from HadCRUT4 (Morice et al., 2012)
blended with sea surface temperature from HadISST4 (Rayner et al., 2003) over the time span of interest. The data is spatially averaged
---
Returns
-------
obs_data_mean : np.array of shape (121, )
Annual spatially averaged observation data from 1900 to 2020.
"""
obs_nc = nc4.Dataset(data_dir + "obs.nc", "r")
obs_temperature_data = obs_nc.variables["temperature_anomaly"][:]
return calculate_spatial_mean(obs_temperature_data)
def calculate_preindustrial_average(forcing, model_name="IPSL", physics=1):
"""
Calculate pre-industrial average between years 1850-1900 for a given forcing and model.
---
Parameters
----------
forcing : str: one of ["hist-GHG", "hist-aer", "hist-nat", "historical"]
type of forcing used in the simulation
model_name : str: one of the 12 models in the model_list
model used in the simulation
physics: int: one of [1, 2]
parameter used for the GISS model
Returns
-------
preindustrial_average : float
The pre-industrial average between the years 1850-1900.
"""
preindustrial_average = np.zeros((36, 72))
# According to authors, for the GISS-E2-1-G, the temperature anomalies were computed separately for the
# simulations using two different physics, with different schemes to calculate the aerosols indirect impact
if model_name == "GISS":
if type == "hist-aer":
if physics == 1:
for i in range(model_dict[model_name][forcing]):
if i < 5 or i > 9:
simu_nc = nc4.Dataset(
f"{data_dir}{model_name}_{forcing}_{i+1}.nc", "r"
)
simu_temperature_data = simu_nc.variables["tas"][0:50]
preindustrial_average += (
np.mean(simu_temperature_data, axis=0) / 7
)
else:
for i in range(model_dict[model_name][forcing]):
if i >= 5 and i <= 9:
simu_nc = nc4.Dataset(
f"{data_dir}{model_name}_{forcing}_{i+1}.nc", "r"
)
simu_temperature_data = simu_nc.variables["tas"][0:50]
preindustrial_average += (
np.mean(simu_temperature_data, axis=0) / 5
)
if type == "historical":
if physics == 1:
for i in range(model_dict[model_name][forcing]):
if i < 10:
simu_nc = nc4.Dataset(
f"{data_dir}{model_name}_{forcing}_{i+1}.nc", "r"
)
simu_temperature_data = simu_nc.variables["tas"][0:50]
preindustrial_average += (
np.mean(simu_temperature_data, axis=0) / 10
)
else:
for i in range(model_dict[model_name][forcing]):
if i >= 10:
simu_nc = nc4.Dataset(
f"{data_dir}{model_name}_{forcing}_{i+1}.nc", "r"
)
simu_temperature_data = simu_nc.variables["tas"][0:50]
preindustrial_average += (
np.mean(simu_temperature_data, axis=0) / 9
)
else:
for i in range(model_dict[model_name][forcing]):
if i >= 5 and i <= 9:
simu_nc = nc4.Dataset(
f"{data_dir}{model_name}_{forcing}_{i+1}.nc", "r"
)
simu_temperature_data = simu_nc.variables["tas"][0:50]
preindustrial_average += np.mean(simu_temperature_data, axis=0) / 5
else:
for i in range(model_dict[model_name][forcing]):
simu_nc = nc4.Dataset(f"{data_dir}{model_name}_{forcing}_{i+1}.nc", "r")
simu_temperature_data = simu_nc.variables["tas"][0:50]
preindustrial_average += (
np.mean(simu_temperature_data, axis=0) / model_dict[model_name][forcing]
)
return preindustrial_average
def get_simulation(simulation_index, forcing, model_name="IPSL", filter=False):
"""
Get a simulation for a given forcing and model.
---
Parameters
----------
simulation_index : int
the index of the requested simulation
forcing : str: one of ["hist-GHG", "hist-aer", "hist-nat", "historical"]
type of forcing used in the simulation
model_name : str: one of the 12 models in the model_list
model used in the simulation
filter : boolean. Defaults to False.
whether to apply a lowpass filter to the GHG and AER forcings
Returns
-------
simulation : np.array of shape (N_years), where N_years equals 115
The data from one simulation for a given forcing and climate model for the years 1900-2014, from which the pre-industrial average is excluded.
"""
# Calculate pre-industrial average
physics = 1
if model_name == "GISS":
if forcing == "hist-aer" and (simulation_index >= 6 and simulation_index <= 10):
physics = 2
elif forcing == "historical" and simulation_index > 10:
physics = 2
preindustrial_average = calculate_preindustrial_average(
forcing, model_name=model_name, physics=physics
)
# Calculate post-industrial 1900-2015 average
simu_nc = nc4.Dataset(
f"{data_dir}{model_name}_{forcing}_{simulation_index}.nc", "r"
)
simu_temperature_data = simu_nc.variables["tas"][50:]
# Subtract preindustrial average from the post-industrial data
simu_temperature_data = simu_temperature_data - preindustrial_average
simulation = calculate_spatial_mean(simu_temperature_data)
if filter:
if forcing == "hist-GHG" or forcing == "hist-aer":
b, a = signal.butter(
20, 1 / 5, btype="lowpass"
) # Lowpass used in the filtrage of the data
simulation = signal.filtfilt(b, a, simulation)
return simulation
def get_all_simulations(forcing, model_name="IPSL", filter=False):
"""
Get all simulations for a given forcing and model.
---
Parameters
----------
forcing : str: one of ["hist-GHG", "hist-aer", "hist-nat", "historical"]
type of forcing used in the simulation
model_name : str: one of the 12 models in the model_list
model used in the simulation
filter : boolean. Defaults to False.
whether to apply a lowpass filter to the GHG and AER forcings
Returns
-------
simulation_data : np.array of shape (N_simu, N_years), where N_simu is dependent on the model and ranges from 3 to 50, and N_years equals 115 and represents the data from 1900-2014
The data from all simulations for a given forcing and climate model for the years 1900-2014, from which the pre-industrial average is excluded.
"""
simulation_data = np.zeros((model_dict[model_name][forcing], 115))
for i in range(model_dict[model_name][forcing]):
simulation_data[i] = get_simulation(
i + 1, forcing=forcing, model_name=model_name, filter=filter
)[0:115]
return simulation_data
def get_model_dataset(model_name="ALL", normalize=True, filter=False):
"""
Get the entire dataset (all simulations for all forcings) for a climate model or all climate models.
---
Parameters
----------
model_name : str: one of the 12 models in the model_list or "ALL" to acquire dataset for all climate models
model used in the simulation
normalize : boolean. Defaults to True.
whether to normalize all simulations by the maximum historical value
filter : boolean. Defaults to False.
whether to apply a lowpass filter to the GHG and AER forcings
Returns
-------
ghg: list of length 12, with one torch.tensor of shape (N_simu, N_years) for each model. N_simu is dependent on the model and ranges from 3 to 50, and N_years equals 115 and represents the data from 1900-2014
A list of tensors, containing the greenhouse gas (GHG) single forcing simulations for each model over the time span of interest.
aer: list of length 12, with one torch.tensor of shape (N_simu, N_years) for each model. N_simu is dependent on the model and ranges from 3 to 50, and N_years equals 115 and represents the data from 1900-2014
A list of tensors, containing the aerosol (AER) single forcing simulations for each model over the time span of interest.
nat: list of length 12, with one torch.tensor of shape (N_simu, N_years) for each model. N_simu is dependent on the model and ranges from 2 to 30, and N_years equals 115 and represents the data from 1900-2014
A list of tensors, containing the natural (NAT) single forcing simulations for each model over the time span of interest.
historical: list of length 12, with one torch.tensor of shape (N_simu, N_years) for each model. N_simu is dependent on the model and ranges from 3 to 65, and N_years equals 115 and represents the data from 1900-2014
A list of tensors, containing the historical (HIST) simulations using all the external forcings as varying boundary conditions for each model over the time span of interest.
maximum_historical_list: list of length 1 or length 12, dependent if model_name=="ALL"
A list of maximum historical values per model
"""
maximum_historical_list = []
if model_name == "ALL":
aer = []
ghg = []
nat = []
historical = []
for model_curr in tqdm(model_list):
print(model_curr)
aer_curr = torch.tensor(
get_all_simulations("hist-aer", model_name=model_curr, filter=filter)[
:, 0:115
]
)
ghg_curr = torch.tensor(
get_all_simulations("hist-GHG", model_name=model_curr, filter=filter)[
:, 0:115
]
)
nat_curr = torch.tensor(
get_all_simulations("hist-nat", model_name=model_curr, filter=filter)[
:, 0:115
]
)
historical_curr = torch.tensor(
get_all_simulations("historical", model_name=model_curr, filter=filter)[
:, 0:115
]
)
historical_max = torch.max(torch.mean(historical_curr, dim=0))
maximum_historical_list.append(historical_max)
if normalize:
aer_curr = aer_curr / historical_max
ghg_curr = ghg_curr / historical_max
nat_curr = nat_curr / historical_max
historical_curr = historical_curr / historical_max
aer.append(aer_curr)
ghg.append(ghg_curr)
nat.append(nat_curr)
historical.append(historical_curr)
else:
aer = torch.tensor(
get_all_simulations("hist-aer", model_name=model_name, filter=filter)[
:, 0:115
]
)
ghg = torch.tensor(
get_all_simulations("hist-GHG", model_name=model_name, filter=filter)[
:, 0:115
]
)
nat = torch.tensor(
get_all_simulations("hist-nat", model_name=model_name, filter=filter)[
:, 0:115
]
)
historical = torch.tensor(
get_all_simulations("historical", model_name=model_name, filter=filter)[
:, 0:115
]
)
historical_max = torch.max(torch.mean(historical, dim=0))
maximum_historical_list.append(historical_max)
if normalize:
aer = aer / historical_max
ghg = ghg / historical_max
nat = nat / historical_max
historical = historical / historical_max
return ghg, aer, nat, historical, np.array(maximum_historical_list)
def train_models(
train_dataloader,
test_dataloader,
lr=0.001,
N_epoch=100,
size_channel=10,
regularization=0,
):
"""
Train the CNN and Linear model.
---
Parameters
----------
train_dataloader : pytorch Dataloader
the data loader for the training set that consists of a sample of simulations from the three forcings for random climate models.
test_dataloader : pytorch Dataloader
the data loader for the test set that consists of a sample of simulations from the three forcings for random climate models.
lr : int
learning rate. Defaults to 1e-3.
N_epoch : int
the number of epochs used to train the model. Defaults to 1e2.
size_channel : int
length of the layer (number of neurons) (defaults to 10)
regularization : float
the amount of regularization used when training the model. Defaults to 0, representing no regularization.
Returns
-------
model_CNN : CNN_Model
a CNN model which takes data from the three single forcing models [ghg, aer, nat] and is trained to predict the historical (HIST) simulations using all the external forcings as varying boundary conditions
loss_train_CNN: list of length N_epoch
list that contains the MSE loss of the model on the training set after each epoch
loss_test_CNN: list of length N_epoch
list that contains the MSE loss of the model on the test set after each epoch
model_linear : Linear_Model
a benchmark linear model which takes data from the three single forcing models [ghg, aer, nat] and is trained to predict the historical (HIST) simulations using all the external forcings as varying boundary conditions
loss_train_linear: list of length N_epoch
list that contains the MSE loss of the model on the training set after each epoch
loss_test_linear: list of length N_epoch
list that contains the MSE loss of the model on the test set after each epoch
"""
model_CNN = CNN_Model(size_channel=size_channel, bias=True)
model_linear = Linear_Model(bias=False)
criterion_CNN = nn.MSELoss()
criterion_linear = nn.MSELoss()
optim_CNN = torch.optim.Adam(
model_CNN.parameters(), lr=lr, weight_decay=regularization
)
optim_linear = torch.optim.Adam(
model_linear.parameters(), lr=lr, weight_decay=regularization
)
loss_train_CNN = []
loss_test_CNN = []
loss_train_linear = []
loss_test_linear = []
for iter in tqdm(range(N_epoch)):
loss_total_train_CNN = 0
loss_total_test_CNN = 0
length_train_CNN = 0
length_test_CNN = 0
loss_total_train_linear = 0
loss_total_test_linear = 0
length_train_linear = 0
length_test_linear = 0
with torch.no_grad():
for X_test, y_test, model_idx in test_dataloader:
y_hat_test_CNN = model_CNN(X_test)
loss_test = criterion_CNN(y_hat_test_CNN.float(), y_test.float())
loss_total_test_CNN += loss_test
length_test_CNN += 1
y_hat_test_linear = model_linear(X_test)
loss_test = criterion_linear(y_hat_test_linear.float(), y_test.float())
loss_total_test_linear += loss_test
length_test_linear += 1
for X_train, y_train, model_idx in train_dataloader:
y_hat_train_CNN = model_CNN(X_train)
loss = criterion_CNN(y_hat_train_CNN.float(), y_train.float())
loss.backward()
optim_CNN.step()
loss_total_train_CNN += loss
optim_CNN.zero_grad()
length_train_CNN += 1
y_hat_train_linear = model_linear(X_train)
loss = criterion_linear(y_hat_train_linear.float(), y_train.float())
loss.backward()
optim_linear.step()
loss_total_train_linear += loss
optim_linear.zero_grad()
length_train_linear += 1
loss_total_train_CNN = loss_total_train_CNN.item() / length_train_CNN
loss_total_test_CNN = loss_total_test_CNN.item() / length_test_CNN
loss_total_train_linear = loss_total_train_linear.item() / length_train_linear
loss_total_test_linear = loss_total_test_linear.item() / length_test_linear
if iter % 10 == 0:
print(f"Iteration {iter}:")
print(
f"\tCNN: training loss: {loss_total_train_CNN:.6f}, test loss {loss_total_test_CNN:.6f}"
)
print(
f"\tLinear: training loss: {loss_total_train_linear:.6f}, test loss {loss_total_test_linear:.6f}"
)
loss_train_CNN.append(loss_total_train_CNN)
loss_test_CNN.append(loss_total_test_CNN)
loss_train_linear.append(loss_total_train_linear)
loss_test_linear.append(loss_total_test_linear)
return (
model_CNN,
np.array(loss_train_CNN),
np.array(loss_test_CNN),
model_linear,
np.array(loss_train_linear),
np.array(loss_test_linear),
)
def train_inverse_model(inputs, target, model, max_iter=100000, alpha=0.005):
"""
Perform backpropagation of the CNN model to obtain the variational inverse model estimates.
---
Parameters
----------
inputs : torch.tensor() of shape (3,115)
a tensor that consists of a sample of simulations from the three forcings for random climate models.
target : torch.tensor() of shape (1,115)
a tensor that consists of the observation data
model : CNN_Model()
the convolutional model trained to predict HIST given [ghg, aer, nat] as input
max_iter : int
the maximum number of iterations used in the model. Defaults to 1e5.
alpha : float
the loss threshold to perform early model stopping. Defaults to 0.005.
Returns
-------
X : torch.tensor()
The input that corresponds to the OBS data as determined by the inverse model
output_estimate: torch.tensor()
The model prediction for the determined input
"""
X = Variable(inputs.clone().detach(), requires_grad=True)
optimizer = torch.optim.Adam([X], lr=0.0001)
criterion = nn.MSELoss()
for iter in range(max_iter):
output_estimate = model(X)
MSE_loss = criterion(output_estimate.float(), target.float())
penalization_term_loss = criterion(X.float(), inputs.float())
loss = MSE_loss + 0.01 * penalization_term_loss
if iter % 10000 == 0:
print(f"Iteration {iter}:")
print(
f"\tInverse model: MSE(OBS, CNN(X)): {MSE_loss:.6f}, MSE(X, inputs) {penalization_term_loss:.6f}"
)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if MSE_loss < alpha:
print(f"Model achieved loss threshold at iteration {iter}:")
break
return X, output_estimate
def get_inverse_model_estimates(
observation_data, model, denormalize=True, filter=False
):
"""
Train the CNN and Linear model.
---
Parameters
----------
observation_data : torch.tensor
a tensor that consists of the observation data
model : CNN_Model
the convolutional model trained to predict HIST given [ghg, aer, nat] as input
denormalize : boolean. Defaults to True.
whether to denormalize all simulations by multiplying by the maximum historical value
filter : boolean. Defaults to False.
whether to apply a lowpass filter to the GHG and AER forcings
Returns
-------
results_list_input: np.array of shape (N_models, N_forcings, N_years), where N_models = 12, N_forcings = 3, N_years = 115
array that contains the inverse model input estimates of the [ghg, aer, nat] by backpropagating using the observation data
results_list_output: np.array of shape (N_models, 1, N_years), where N_models = 12, N_years = 115
array that contains the inverse model output estimates
"""
results_list_input = []
results_list_output = []
for i in tqdm(range(len(model_list))):
ghg, aer, nat, historical, maximum_historical_list = get_model_dataset(
model_name=model_list[i], normalize=True, filter=filter
)
dataloader_inverse_model = DataLoader(
MonDataset_Inverse(ghg, aer, nat), batch_size=1
)
for inputs in dataloader_inverse_model:
X, output_estimate = train_inverse_model(
inputs, observation_data, model, max_iter=100000
)
X = X.clone().detach().numpy()
output_estimate = output_estimate.clone().detach().numpy()
if denormalize:
X *= maximum_historical_list[-1]
output_estimate *= maximum_historical_list[-1]
results_list_input.append(X)
results_list_output.append(output_estimate)
results_list_input = np.array(results_list_input)[:, 0]
results_list_output = np.array(results_list_output)[:, 0]
with open("./Results/Inverse_Results.npy", "wb") as f1:
np.save(f1, results_list_input)
return results_list_input, results_list_output
Pipeline#
Fetch data#
The data can be found in a compressed file data_pre_ind_2 at ConstantinBone/detection-and-attribution-of-climate-change-a-deep-learning-and-variational-approach. We use pooch to fetch and unzip them directly from the GitLab repository.
pooch.retrieve(
url="https://gitlab.com/ConstantinBone/detection-and-attribution-of-climate-change-a-deep-learning-and-variational-approach/-/raw/main/data_pre_ind_2.zip",
known_hash=None,
processor=pooch.Unzip(extract_dir="data"),
path=f".",
progressbar=True,
)
Show code cell output
Downloading data from 'https://gitlab.com/ConstantinBone/detection-and-attribution-of-climate-change-a-deep-learning-and-variational-approach/-/raw/main/data_pre_ind_2.zip' to file '/home/jovyan/0a6cabc0997ee6e6c798a5a8eeb76710-data_pre_ind_2.zip'.
100%|███████████████████████████████████████| 799M/799M [00:00<00:00, 1.45TB/s]
SHA256 hash of downloaded file: 5199a20e4f37f4bba14cb2b2630fff6d38b9e82cfbb683d4da209b25920020e2
Use this value as the 'known_hash' argument of 'pooch.retrieve' to ensure that the file hasn't changed if it is downloaded again in the future.
Unzipping contents of '/home/jovyan/0a6cabc0997ee6e6c798a5a8eeb76710-data_pre_ind_2.zip' to '/home/jovyan/data'
['/home/jovyan/data/data_pre_ind_2/IPSL_historical_29.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_65.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_46.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_34.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_20.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_35.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_27.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_8.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_19.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_54.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_15.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_8.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_30.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_7.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_28.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_13.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_9.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_9.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_7.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_48.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_20.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_16.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_10.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_14.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_7.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_13.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_9.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_55.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_21.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_6.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_28.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_45.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_8.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_31.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_7.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_21.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_32.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_14.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_4.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_36.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_63.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_6.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_5.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_61.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_64.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_15.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_33.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_25.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_7.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_14.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_19.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_19.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_5.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_11.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_7.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_38.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_47.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_19.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_43.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_7.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_11.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_10.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_7.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_6.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_39.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_10.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_19.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_spe.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_18.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_14.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_32.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_24.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_9.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_historical_7.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_29.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_30.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_14.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_7.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_27.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_8.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_53.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_12.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_41.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_18.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-nat_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_42.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_40.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_50.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_25.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_18.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_38.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_23.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_25.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_10.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_19.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_17.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_13.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_47.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_13.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_14.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_34.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_6.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_11.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_5.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_49.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_12.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_26.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_28.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_9.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_24.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_20.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_17.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_18.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_5.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_23.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_40.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_52.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_18.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_8.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_25.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_15.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_19.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_6.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_10.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_5.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_49.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_29.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_60.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_9.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_12.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_8.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_22.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_42.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_18.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_21.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_58.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_9.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_11.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_6.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_22.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_46.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_28.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_62.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_46.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_9.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-GHG_4.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_43.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_10.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_17.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_8.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_36.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_8.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_4.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_24.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_25.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_33.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_44.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_9.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_13.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_39.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_24.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_40.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_41.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_7.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_6.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_32.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_29.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_32.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_8.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_11.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_10.nc',
'/home/jovyan/data/data_pre_ind_2/obs.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_41.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_11.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_31.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_17.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_45.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_6.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_11.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-nat_5.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_17.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_45.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_15.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_10.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_11.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_51.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_47.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_22.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_37.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_18.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_16.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_15.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_21.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_27.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_42.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_10.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_26.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_27.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_9.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_15.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_17.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_4.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_15.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_26.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_26.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_18.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_5.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_19.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_10.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_5.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_30.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_16.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_9.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_19.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_19.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_24.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_30.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_30.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_29.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_17.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_43.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_25.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_4.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_8.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_10.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_20.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-GHG_5.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_30.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_28.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_5.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_18.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_28.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_44.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_20.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_28.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_27.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_50.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_40.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_22.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_16.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_13.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_39.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_12.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_12.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_36.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_22.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_48.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_49.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_17.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_11.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_12.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_27.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_23.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_37.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_7.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_16.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_44.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_8.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-aer_5.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_23.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_9.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_9.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_12.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_11.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_38.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_47.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_11.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-GHG_4.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_27.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_6.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-aer_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_10.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_33.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_34.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_12.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-nat_4.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_13.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_49.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_7.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_8.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_32.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_5.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_28.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_20.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_16.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_23.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_7.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_16.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_5.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_12.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_23.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_7.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_8.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_23.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_7.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_22.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_50.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-aer_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_17.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_10.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_14.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_7.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_9.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_24.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_16.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_31.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_44.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_38.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_15.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-aer_6.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_31.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_24.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_34.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_20.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_9.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-nat_8.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_29.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_8.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_20.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-GHG_9.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_27.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_42.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_14.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_7.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_30.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_4.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_39.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_12.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_26.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_45.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_8.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_59.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_20.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_26.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-aer_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_29.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_35.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_21.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_56.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_7.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_25.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_22.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_41.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_24.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-GHG_3.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_46.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_14.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_9.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_15.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_21.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_43.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_9.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_10.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_4.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/FGOALS_historical_6.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_14.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_8.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_8.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_historical_1.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_26.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_5.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_48.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_48.nc',
'/home/jovyan/data/data_pre_ind_2/BCC_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_21.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_21.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_35.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_historical_7.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_10.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_5.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_37.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_23.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_15.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_1.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_50.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_31.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_30.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_10.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_37.nc',
'/home/jovyan/data/data_pre_ind_2/HadGEM3_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_5.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_6.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-GHG_1.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_2.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_8.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-GHG_10.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_11.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_36.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_13.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_13.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_33.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_historical_10.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_18.nc',
'/home/jovyan/data/data_pre_ind_2/IPSL_hist-aer_9.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_25.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_35.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_12.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/CNRM_hist-nat_4.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_29.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-nat_16.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_13.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-GHG_22.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_4.nc',
'/home/jovyan/data/data_pre_ind_2/NorESM2_hist-GHG_2.nc',
'/home/jovyan/data/data_pre_ind_2/GISS_hist-nat_1.nc',
'/home/jovyan/data/data_pre_ind_2/CESM2_hist-nat_2.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_16.nc',
'/home/jovyan/data/data_pre_ind_2/ACCESS_historical_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_historical_57.nc',
'/home/jovyan/data/data_pre_ind_2/ESM2_hist-nat_3.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_26.nc',
'/home/jovyan/data/data_pre_ind_2/MIRO_historical_17.nc',
'/home/jovyan/data/data_pre_ind_2/CanESM5_hist-aer_6.nc']
Load data#
We first start by acquiring the annual OBS data of the 2 m air temperature over the continents from HadCRUT4 blended with sea surface temperature from HadISST4. The data is spatially averaged over the globe and only the time span of interest (1900 - 2014) is acquired. To make OBS and HIST comparable, OBS is corrected of its blending effects using a 1.06 multiplier coefficient (Richardson et al., 2018). Finally, the OBS data is normalized to a maximum of 1 by dividing the series with the OBS maximum.
We then get the simulation data for all forcings (GHG, AER, NAT, HIST) of all 12 climate models. The simulation data is spatially averaged over the globe to create an annual mean from which the pre-industrial average is subtracted. The simulations are then also max-normalized by dividing with the historical maximum.
# Set input data dir
data_dir = "data/data_pre_ind_2/"
# Get observation data
observation_data = torch.tensor(get_observation_data(data_dir))[0:115] * 1.06
observation_max = torch.max(observation_data)
observation_data = observation_data / observation_max
# Get the simulation data for all forcings and all climate models
ghg, aer, nat, historical, maximum_historical_list = get_model_dataset(
model_name="ALL", normalize=True, filter=False
)
N_simu_table_list = []
for i in range(len(model_list)):
N_simu_table_list.append(
[
model_dict[model_list[i]]["long_name"],
ghg[i].shape[0],
aer[i].shape[0],
nat[i].shape[0],
historical[i].shape[0],
]
)
N_simu_table = pd.DataFrame(
N_simu_table_list, columns=["Model", "GHG", "AER", "NAT", "HIST"]
)
0%| | 0/12 [00:00<?, ?it/s]
CanESM5
8%|▊ | 1/12 [00:41<07:36, 41.46s/it]
CNRM
17%|█▋ | 2/12 [00:48<03:29, 20.95s/it]
IPSL
25%|██▌ | 3/12 [00:55<02:11, 14.62s/it]
ACCESS
33%|███▎ | 4/12 [01:00<01:26, 10.84s/it]
BCC
42%|████▏ | 5/12 [01:01<00:50, 7.23s/it]
FGOALS
50%|█████ | 6/12 [01:02<00:30, 5.14s/it]
HadGEM3
58%|█████▊ | 7/12 [01:03<00:19, 3.89s/it]
MIRO
67%|██████▋ | 8/12 [01:14<00:24, 6.15s/it]
ESM2
75%|███████▌ | 9/12 [01:16<00:14, 4.78s/it]
NorESM2
83%|████████▎ | 10/12 [01:17<00:07, 3.59s/it]
CESM2
92%|█████████▏| 11/12 [01:18<00:02, 2.97s/it]
GISS
100%|██████████| 12/12 [01:23<00:00, 6.92s/it]
Show code cell source
table1_models_fig = plt.figure(figsize=(8, 0.16))
rcolors = plt.cm.BuPu(np.full(len(N_simu_table.index), 0.3))
ccolors = plt.cm.BuPu(np.full(len(N_simu_table.columns), 0.3))
plt.table(
cellText=N_simu_table.values,
rowLabels=N_simu_table.index,
colLabels=N_simu_table.columns,
cellLoc="center",
rowColours=rcolors,
colColours=ccolors,
)
# add title to table
plt.title("Number of Simulations per Model per Forcing")
# turn axes off
plt.axis("off")
table1_models_fig.canvas.draw()
plt.show()
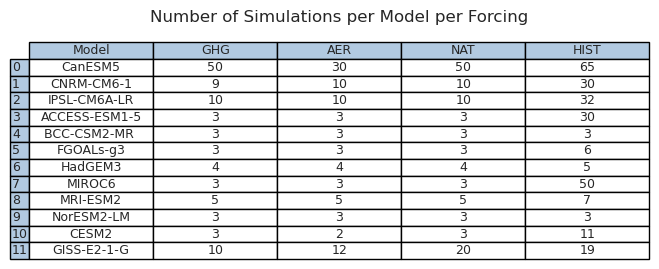
To visualize the intra-specific and inter-specific variation of the simulations for the 12 climate models, we plot the three single-forcing simulations: GHG (orange), AER (yellow), NAT (blue) and the historical simulation using all external forcings: HIST (olive) for each model. The mean value of the simulations per forcing are shown with a solid line, while the shaded color represents one standard deviation off the mean. The observation data: OBS is also shown with a black dotted line.
Show code cell source
fig1_models, ax = plt.subplots(figsize=(16, 10), ncols=4, nrows=3)
plt.suptitle("Visualization of the simulations of the 12 models", fontsize=20)
for i in range(len(model_list)):
plt.subplot(3, 4, i + 1)
plt.title(model_dict[model_list[i]]["long_name"])
for j, (forcing, forcing_name) in enumerate(
zip([ghg, aer, nat, historical], ["GHG", "AER", "NAT", "HIST"])
):
forcing_mean = torch.mean(forcing[i], axis=0)
forcing_std = torch.std(forcing[i], axis=0)
plt.plot(
forcing_mean,
color=color_palette[j],
linewidth=3,
alpha=0.8,
label=forcing_name,
)
plt.fill_between(
np.arange(115),
forcing_mean - forcing_std,
forcing_mean + forcing_std,
color=color_palette[j],
alpha=0.3,
)
plt.plot(
observation_data,
color="#444444",
linestyle=":",
linewidth=3,
alpha=1,
label="OBS",
)
plt.ylim(-2.5, 2.5)
plt.xticks(
np.linspace(0, 120, 5),
[str(tick + 1900) for tick in np.linspace(0, 120, 5, dtype=int)],
)
plt.yticks(
np.linspace(-2.5, 2.5, 5),
[str(np.round(tick, 2)) for tick in np.linspace(-2.5, 2.5, 5, dtype=float)],
)
if i == 0:
handles, labels = ax[0, 0].get_legend_handles_labels()
plt.legend(
handles, ["GHG", "AER", "NAT", "HIST", "OBS"], loc="upper left", fontsize=10
)
if i % 4 == 0:
plt.ylabel(f"GMST (\N{DEGREE SIGN}C)", fontsize=13)
if i > 7:
plt.xlabel(f"Years", fontsize=13)
plt.tight_layout()
plt.show()
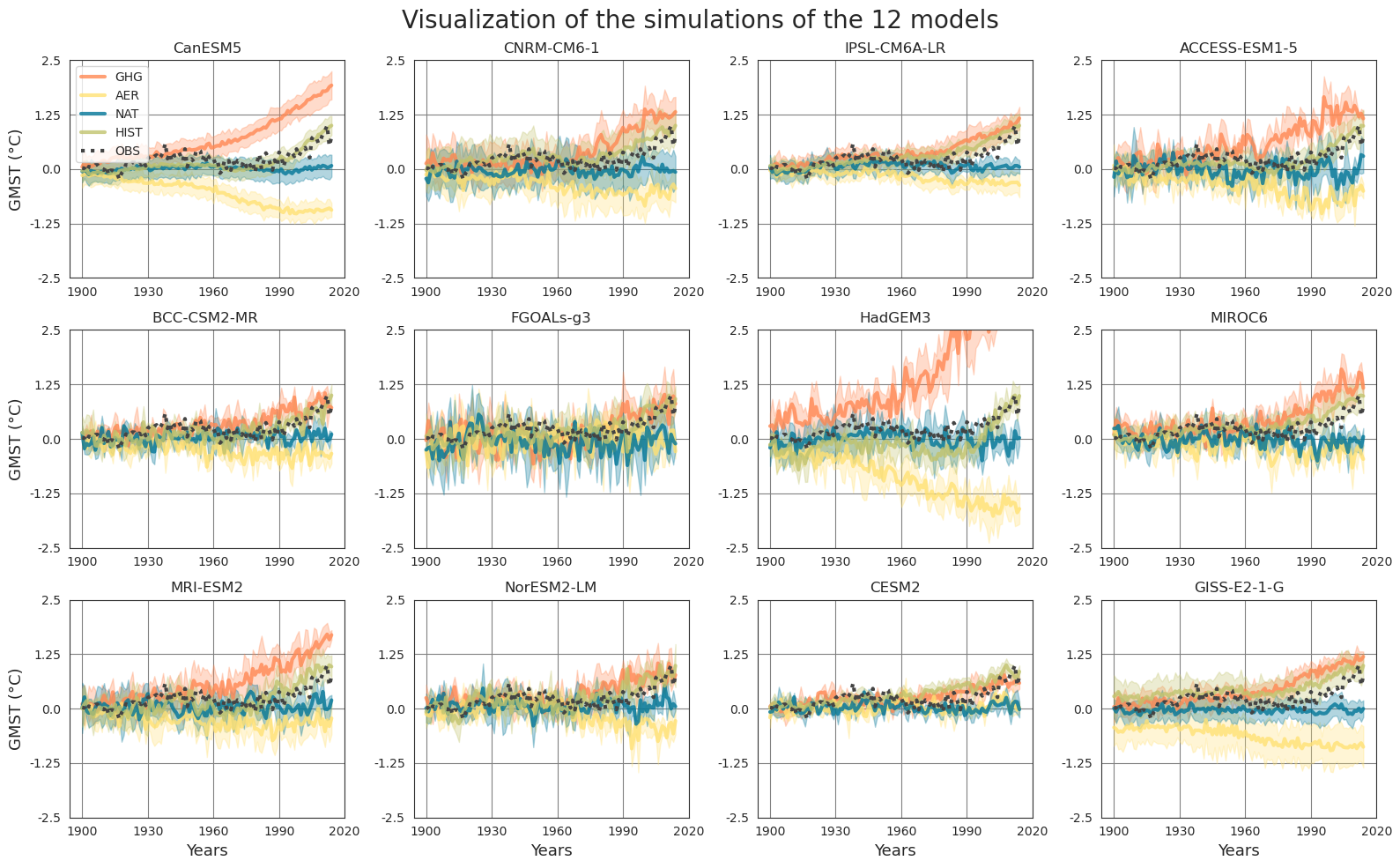
The following figure shows the variation of the forcings across all 12 climate models. The same color code as the previous figure is used.
Show code cell source
fig_models_mean, ax = plt.subplots(figsize=(8, 5), ncols=1, nrows=1)
plt.suptitle(
"Mean and standard deviation of the simulations of the 12 models", fontsize=20
)
for j, (forcing, forcing_name) in enumerate(
zip([ghg, aer, nat, historical], ["GHG", "AER", "NAT", "HIST"])
):
forcing_mean = torch.mean(torch.cat(forcing), axis=0)
forcing_std = torch.std(torch.cat(forcing), axis=0)
plt.plot(
forcing_mean, color=color_palette[j], linewidth=3, alpha=0.8, label=forcing_name
)
plt.fill_between(
np.arange(115),
forcing_mean - forcing_std,
forcing_mean + forcing_std,
color=color_palette[j],
alpha=0.3,
)
plt.plot(
observation_data, color="#444444", linestyle=":", linewidth=3, alpha=1, label="OBS"
)
plt.ylim(-2.5, 2.5)
plt.xticks(
np.linspace(0, 120, 5),
[str(tick + 1900) for tick in np.linspace(0, 120, 5, dtype=int)],
)
plt.yticks(
np.linspace(-2.5, 2.5, 5),
[str(np.round(tick, 2)) for tick in np.linspace(-2.5, 2.5, 5, dtype=float)],
)
plt.ylabel(f"GMST (\N{DEGREE SIGN}C)", fontsize=13)
plt.xlabel(f"Years", fontsize=13)
handles, labels = ax.get_legend_handles_labels()
plt.legend(handles, ["GHG", "AER", "NAT", "HIST", "OBS"], loc="upper left", fontsize=10)
plt.tight_layout()
plt.show()
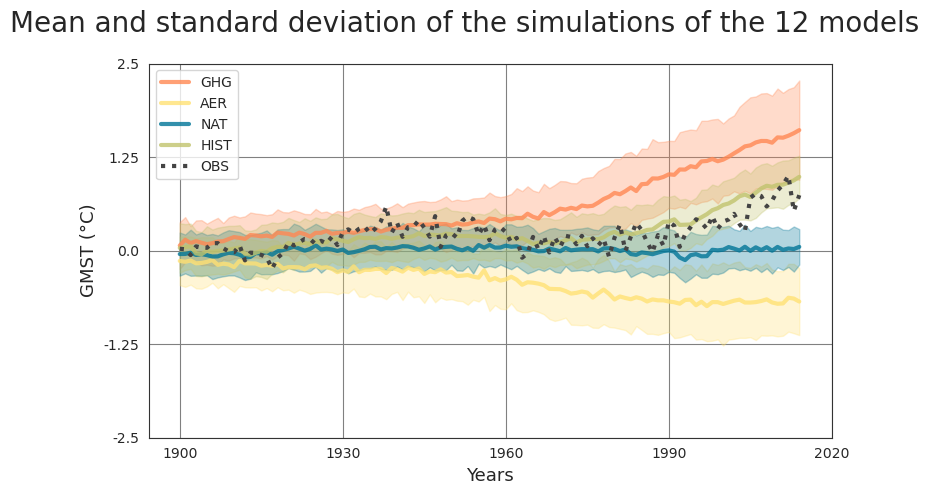
CNN#
Model training#
Note:
If relevant, you can train CNN models in your available local/remote machine by converting below Python markdown cells to code. The current version load pretrained models in .pkl format available in outputs/models.
To train the model for the detection of climate change given the single-forcing simulations, we first define a custom dataloader. The data loader works such that it randomly picks a model and a simulation index to create a data sample of input (GHG, AER, NAT) and a target (HIST).
BATCH_SIZE = 100
train_dataloader = DataLoader(MonDataset(ghg, aer, nat, historical, model_of_interest = -1, dataset_type = 'train'), shuffle=True, batch_size=BATCH_SIZE)
test_dataloader = DataLoader(MonDataset(ghg, aer, nat, historical, model_of_interest = -1, dataset_type = 'test'), shuffle=True, batch_size=BATCH_SIZE)
The train and test dataloaders are then used as input to a convolutional network with three convolutional layers and a hyperbolic tangent activation function. As a result of the function, we receive the trained CNN model, as well as a linear model which is used for comparison.
model_CNN, loss_train_CNN, loss_test_CNN, model_linear, loss_train_linear, loss_test_linear = train_models(train_dataloader, test_dataloader, N_epoch = 100)
## Save training/test curves
loss_df = pd.DataFrame({'loss_train_CNN': loss_train_CNN, 'loss_train_linear': loss_train_linear,
'loss_test_CNN': loss_test_CNN, 'loss_test_linear': loss_test_linear})
loss_df.to_csv('outputs/results/models_loss_history.csv')
## Save models
pickle.dump(model_CNN, open('Models/CNN_model.pkl', 'wb'))
pickle.dump(model_linear, open('Models/Linear_model.pkl', 'wb'))
Model performance#
## Load models
model_linear = pickle.load(open("outputs/models/Linear_model.pkl", "rb"))
model_CNN = pickle.load(open("outputs/models/CNN_model.pkl", "rb"))
## Load loss curves
loss_curves_df = pd.read_csv("outputs/models/models_loss_history.csv")
Show code cell source
skip_first_epochs = 5
fig_train_history, ax = plt.subplots(figsize=(8, 5), ncols=1, nrows=1)
plt.suptitle("Loss per Epoch of the CNN and Linear models", fontsize=20)
for i, (loss_list, dataset_type) in enumerate(
zip(
[loss_curves_df["loss_train_CNN"], loss_curves_df["loss_test_CNN"]],
["Train", "Test"],
)
):
plt.plot(
loss_list[skip_first_epochs:],
color=color_palette[i + 1],
linestyle="-",
linewidth=3,
alpha=0.8,
label=f"CNN Model {dataset_type} Loss",
)
for i, (loss_list, dataset_type) in enumerate(
zip(
[loss_curves_df["loss_train_linear"], loss_curves_df["loss_test_linear"]],
["Train", "Test"],
)
):
plt.plot(
loss_list[skip_first_epochs:],
color=color_palette[i + 1],
linestyle="--",
linewidth=3,
alpha=0.8,
label=f"Linear Model {dataset_type} Loss",
)
plt.xlabel("# Epochs")
plt.ylabel("MSE Loss")
plt.yscale("log")
plt.legend(loc="upper right", fontsize=10)
plt.tight_layout()
plt.show()
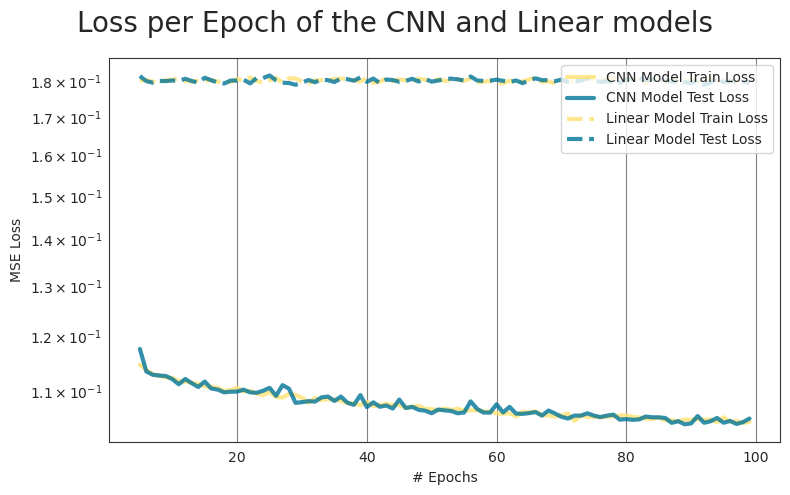
Inverse model#
Note:
This step benefits from GPU’s processing power. We suggest to run the get_inverse_model_estimates in your available local/remote machine (e.g. Colab) by converting below Python markdown cell to code. The current version load results in .npy format available in outputs/results.
Finally, we use trained CNN model to estimate the contribution of each forcing in the multi-model dataset using variational inversion. This is done by using the OBS data as the target variable of the CNN model and backpropagating until we get estimates of the input.
results_list_input, results_list_output = get_inverse_model_estimates(observation_data, model_CNN, denormalize = False)
# Load inverse model results
results_list_input = np.load("./outputs/results/Inverse_Results.npy")
Now we visualize the variational inverse model estimates for each model compared to the climate model simulations. We plot the three single-forcing simulations: GHG (orange), AER (yellow), NAT (blue) for the inverse estimates (dashed line) and the original climate model simulations (solid line). The color shades show one standard deviation across the inversion (dashed area) and the simulations. The observation data: OBS is also shown with a black dotted line.
Show code cell source
fig_inverse_models, ax = plt.subplots(figsize=(16, 10), ncols=4, nrows=3)
plt.suptitle(
"Mean and standard deviation of the inverse model estimates of the simulations",
fontsize=20,
)
for i in range(len(model_list)):
plt.subplot(3, 4, i + 1)
plt.title(model_dict[model_list[i]]["long_name"])
for j, (forcing, forcing_name) in enumerate(
zip([ghg, aer, nat], ["GHG", "AER", "NAT"])
):
forcing_mean = torch.mean(forcing[j], axis=0)
forcing_std = torch.std(forcing[j], axis=0)
forcing_mean_inverse = np.mean(
results_list_input[100 * i : 100 * (i + 1)], axis=0
)[j]
forcing_std_inverse = np.std(
results_list_input[100 * i : 100 * (i + 1)], axis=0
)[j]
plt.plot(
forcing_mean,
color=color_palette[j],
linestyle="-",
linewidth=3,
alpha=0.8,
label=forcing_name,
)
plt.fill_between(
np.arange(115),
forcing_mean - forcing_std,
forcing_mean + forcing_std,
color=color_palette[j],
alpha=0.3,
)
plt.plot(
forcing_mean_inverse,
color=color_palette[j],
linestyle="--",
linewidth=3,
alpha=0.8,
label=forcing_name,
)
plt.fill_between(
np.arange(115),
forcing_mean_inverse - forcing_std_inverse,
forcing_mean_inverse + forcing_std_inverse,
hatch="////",
color="black",
facecolor=color_palette[j],
alpha=0.3,
)
plt.plot(
observation_data,
color="#444444",
linestyle=":",
linewidth=3,
alpha=1,
label="OBS",
)
plt.ylim(-2.5, 2.5)
plt.xticks(
np.linspace(0, 120, 5),
[str(tick + 1900) for tick in np.linspace(0, 120, 5, dtype=int)],
)
plt.yticks(
np.linspace(-2.5, 2.5, 5),
[str(np.round(tick, 2)) for tick in np.linspace(-2.5, 2.5, 5, dtype=float)],
)
if i == 0:
handles, labels = ax[0, 0].get_legend_handles_labels()
plt.legend(
handles, ["GHG", "AER", "NAT", "HIST", "OBS"], loc="upper left", fontsize=10
)
if i % 4 == 0:
plt.ylabel(f"GMST (\N{DEGREE SIGN}C)", fontsize=13)
if i > 7:
plt.xlabel(f"Years", fontsize=13)
plt.tight_layout()
plt.show()
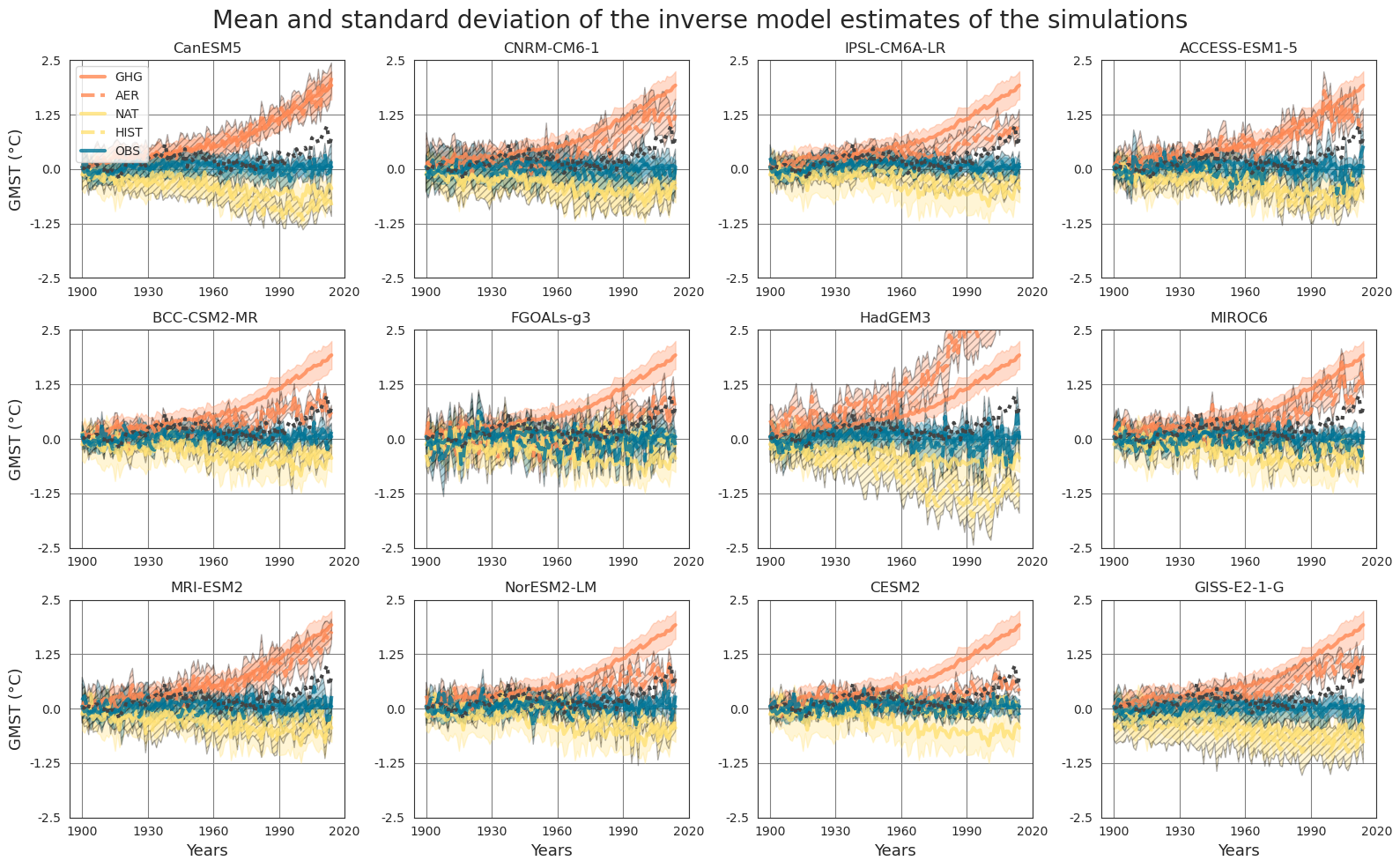
The following figure visualizes the same figure by taking all models into account. The same color as the previous figure is used.
Show code cell source
fig_inverse_models_mean, ax = plt.subplots(figsize=(8, 5), ncols=1, nrows=1)
plt.suptitle(
"Mean and standard deviation of the inverse model estimates of the simulations",
fontsize=20,
)
for i, (forcing, forcing_name) in enumerate(
zip([ghg, aer, nat], ["GHG", "AER", "NAT"])
):
forcing_std = torch.std(torch.cat(forcing), axis=0)
forcing_mean = torch.mean(torch.cat(forcing), axis=0)
forcing_mean_inverse = np.mean(results_list_input, axis=0)[i]
forcing_std_inverse = np.std(results_list_input, axis=0)[i]
plt.plot(
forcing_mean,
color=color_palette[i],
linestyle="-",
linewidth=3,
alpha=0.8,
label=forcing_name,
)
plt.fill_between(
np.arange(115),
forcing_mean - forcing_std,
forcing_mean + forcing_std,
color=color_palette[i],
alpha=0.3,
)
plt.plot(
forcing_mean_inverse,
color=color_palette[i],
linestyle="--",
linewidth=3,
alpha=0.8,
label=forcing_name,
)
plt.fill_between(
np.arange(115),
forcing_mean_inverse - forcing_std_inverse,
forcing_mean_inverse + forcing_std_inverse,
hatch="////",
color="black",
facecolor=color_palette[i],
alpha=0.3,
)
plt.plot(
observation_data, color="#444444", linestyle=":", linewidth=3, alpha=1, label="OBS"
)
plt.ylim(-2.5, 2.5)
plt.xticks(
np.linspace(0, 120, 5),
[str(tick + 1900) for tick in np.linspace(0, 120, 5, dtype=int)],
)
plt.yticks(
np.linspace(-2.5, 2.5, 5),
[str(np.round(tick, 2)) for tick in np.linspace(-2.5, 2.5, 5, dtype=float)],
)
plt.xlabel(f"Years", fontsize=13)
plt.ylabel(f"GMST (\N{DEGREE SIGN}C)", fontsize=13)
handles, labels = ax.get_legend_handles_labels()
plt.legend(
handles,
[
"GHG",
"Inversion of GHG",
"AER",
"Inversion of AER",
"NAT",
"Inversion of NAT",
"OBS",
],
loc="upper left",
fontsize=10,
)
plt.tight_layout()
plt.show()
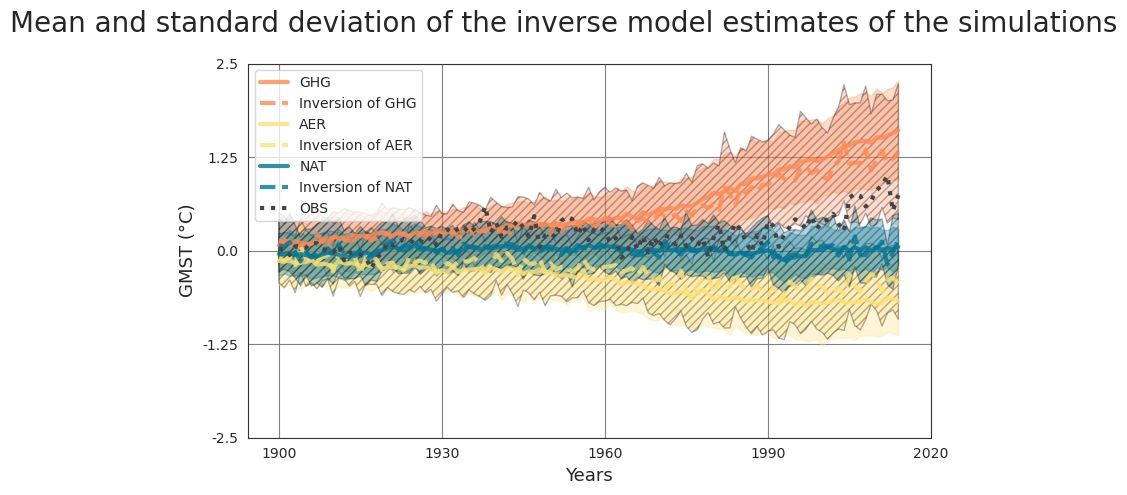
Finally, we visualize the mean and standard deviation of the variational inverse model estimates over time, and further show the results for two years, in this case 1993 and 2014 for greenhouse gases (orange), anthropogenic aerosols (yellow) and natural forcings (blue).
Show code cell source
fig2_inverse_estimates, ax = plt.subplots(
figsize=(12.4, 4.8), ncols=3, nrows=1, gridspec_kw={"width_ratios": [3, 1, 1]}
)
plt.suptitle(
"Mean and standard deviation of the inverse model estimates of the simulations",
fontsize=20,
)
plt.subplot(1, 3, 1)
for i, (forcing, forcing_name) in enumerate(
zip([ghg, aer, nat], ["GHG", "AER", "NAT"])
):
forcing_mean_inverse = np.mean(results_list_input, axis=0)[i]
forcing_std_inverse = np.std(results_list_input, axis=0)[i]
plt.plot(
forcing_mean_inverse,
color=color_palette[i],
linestyle="--",
linewidth=3,
alpha=0.8,
label=forcing_name,
)
plt.fill_between(
np.arange(115),
forcing_mean_inverse - forcing_std_inverse,
forcing_mean_inverse + forcing_std_inverse,
color=color_palette[i],
alpha=0.3,
)
plt.plot(
observation_data, color="#444444", linestyle=":", linewidth=3, alpha=1, label="OBS"
)
plt.ylim(-2.5, 2.5)
plt.xticks(
np.linspace(0, 120, 5),
[str(tick + 1900) for tick in np.linspace(0, 120, 5, dtype=int)],
)
plt.yticks(
np.linspace(-2.5, 2.5, 5),
[str(np.round(tick, 2)) for tick in np.linspace(-2.5, 2.5, 5, dtype=float)],
)
plt.xlabel(f"Years", fontsize=13)
plt.ylabel(f"GMST (\N{DEGREE SIGN}C)", fontsize=13)
handles, labels = ax[0].get_legend_handles_labels()
plt.legend(
handles,
["Inversion of GHG", "Inversion of AER", "Inversion of NAT", "OBS"],
loc="upper left",
fontsize=10,
)
for j, year in enumerate([1993, 2014]):
plt.subplot(1, 3, j + 2)
year_ind = year - 1900
for i, forcing_name in enumerate(["GHG", "AER", "NAT"]):
result_forcing_year = results_list_input[:, i, year_ind]
# bin = int(round((np.max(result_forcing_year) - np.min(result_forcing_year)) * 10)) +1
plt.hist(
results_list_input[:, i, year_ind],
bins=np.linspace(-2.5, 2.5, 30),
alpha=0.5,
color=color_palette[i],
orientation="horizontal",
)
plt.ylim(-2.5, 2.5)
plt.title(year)
plt.xlabel(f"Frequency", fontsize=13)
plt.ylabel(f"GMST (\N{DEGREE SIGN}C)", fontsize=13)
plt.tight_layout()
plt.show()
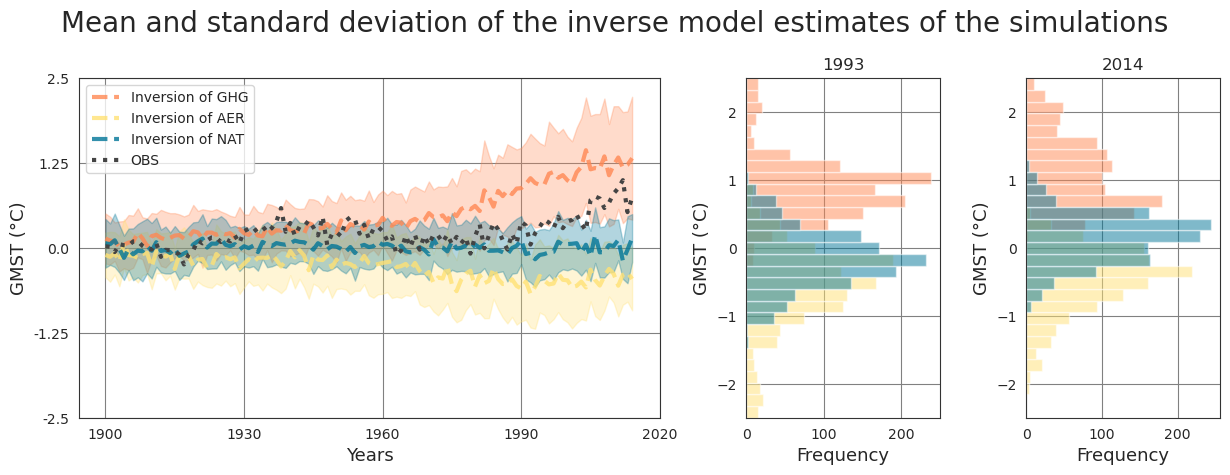
As we can see in the left panel of the image, the results are comparable to the original simulations, however, with a slightly increased standard deviation. The right panel illustrates the distribution of the results from the inversions in 1993 and 2014, showing a clear delineation between the effect of GHG compared to AER and NAT forcings. Furthermore, this results obtained in this run of the notebook slighly differ from the ones in the original paper. This could be due to multiple reasons, such as the stochasticity involved in training the models or slight differences in the pipeline compared to the original paper.
Limitations#
Data uncertainty: The analysis relies on the the accuracy and quality of the data which is used to train the models. However, especially when using the climate simulation data (GHG, AER, NAT, HIST), we rely on the use of climate models which inherently carry uncertainties due to simplified representations of complex climate processes, thus can bias the changes to specific forcings.
Spatiotemporal resolution: The analysis provides GMST attribution on a global scale, but it may not capture regional variations adequately. Regional climate responses and localized forcings might not be fully accounted for, limiting the ability to attribute changes at finer spatial scales. However, this is something the authors of the paper discuss they will research in future work.
Incomplete forcings: The analysis focuses on attributing GMST changes to well-mixed greenhouse gases, anthropogenic aerosols, and natural forcings. However, other external factors, such as land-use changes or solar variability, may also contribute to GMST variations and are not explicitly considered in this analysis.
Future projection uncertainty: The analysis focuses on historical data up to 2014, and the attribution results may not fully reflect potential changes beyond that period. Projecting the attribution results into the future introduces additional uncertainties related to emission scenarios and climate model projections.
Sensitivity to methodology: The results of the analysis may be sensitive to the specific methodology chosen, including the design of the variational inversion approach and the choice of climate models used. Alternative methodologies could yield different attribution outcomes.
Summary#
The climate change attribution problem is a very important issue that pertains to understanding the exact causes behind climate change. However, most approaches tackling this problem have relied on the classical forcing additivity assumption which precludes any non-linear combinations that are ubiquitous in nature.
In this notebook, we utilize a CNN architecture to escape this constraint and estimate the historical global mean surface temperature using single forcing simulations (greenhouse gases, anthropogenic aerosols and natural forcings) from ocean-atmosphere general circulation models from the Coupled Model Intercomparison Project 6 (CMIP6).
The results show that the CNN performs better and obtains a lower mean square error compared to a simpler linear model trained on the same data.
The trained CNN is then used with a variational inversion approach to estimate the single forcings when given observation data from HadCRUT4 and HAdISST412. The estimated inversions of the single forcings show high similarity to the original data and provide coherent results with larger confidence intervals.
Citing this Notebook#
Please see CITATION.cff for the full citation information. The citation file can be exported to APA or BibTex formats (learn more here).
Additional information#
Dataset: Bône, Constantin. (2023). Detection and attribution of climate change a Deep Learning and Variational approach. ConstantinBone/detection-and-attribution-of-climate-change-a-deep-learning-and-variational-approach/-/blob/main/data_pre_ind_2.zip - Commit 8dff0335be7dbf07e56c7a99bef6b12453360012
License: The code in this notebook is licensed under the MIT License. The Environmental Data Science book is licensed under the Creative Commons by Attribution 4.0 license. See further details here.
Contact: If you have any suggestion or report an issue with this notebook, feel free to create an issue or or send a direct message to environmental.ds.book@gmail.com.
Notebook repository version: v1.0.3
Last tested: 2024-03-11